 RabbitMQ
RabbitMQ
# 1 消息数量限制
RabbitMQ上一个queue中存放的message是否有数量限制?
可以认为是无限制的,因为限制取决于机器内存。
# 2 RabbitMQ消息丢失
丢失数据分为:生产者丢失消息、消息列表丢失消息、消费者丢失消息。
# 2.1 生产者丢失消息
生产者丢失消息可以通过ACK方式处理,消息投递到所有匹配的队列之后,rabbitMQ就会发送一个ACK给生产者。
# 2.2 消息列表丢失消息
消息列表丢失可以开启持久化磁盘的配置,在消息持久化到磁盘后再给生产者发送ACK信号。
操作步骤:
- 将queue的持久化标识durable设置为true,则代表是一个持久的队列
- 发送消息的时候将deliveryMode=2
# 2.3 消费者丢失消息
消费者丢失消息一般是因为采用了自动确认消息模式,消费者在收到消息之后,处理消息之前会自动回复RabbitMQ已收到消息,如果这时处理消息失败,就会丢失消息。解决方案:
- 处理消息成功后,手动回复确认消息
# 3 RabbitMQ的消息投递流程是怎样的?
Producer --> RabbitMQ Broker --> Exchange --> Queue --> Consumer
# 4 生产端怎么保证消息可靠性投递?
消息从producer到exchange会返回一个confirmCallback。
消息从exchange到queue投递失败会返回一个returnCallback。
利用这两个callback可以控制消息的可靠性投递。
- ConfirmCallback
设置publisher-confirm="true"开启确认模式。
在方法中判断ack,如果为true,则发送成功,如果为false,则发送失败。


- ReturnCallback
设置publisher-returns="true"开启退回模式。
消息从exchange路由到queue失败后触发回调。


# 5 消费者收到消息后有几种确认方式?
有三种确认方式:
- 自动确认:acknowledge="none" (自动ack)
- 手动确认:acknowledge="manual" (手动ack)
- 根据异常情况确认:acknowledge="auto",(这种方式使用麻烦,一般不用)
自动确认:消费者丢失消息一般是因为采用了自动确认消息模式,消费者在收到消息之后,处理消息之前会自动回复RabbitMQ已收到消息,如果这时处理消息失败,就会丢失消息。
# 6 RabbitMQ消息重复消费
# 6.1 为什么会重复消费?
正常情况,消费者在消费消息的时候,消费完毕会发送一个确认消息给消息队列,消息队列就知道该消息被消费了,就会将该消息从消息队列中删除。
但是因为网络传输等故障,确认消息没有传送到消息队列,导致消息队列不知道已经消费过该消息,再次将消息分发给其他消费者。
# 6.2 怎么解决消息重复消费问题?
解决思路:保证消息幂等性
# 7 RabbitMQ消息堆积
# 7.1 为什么会出现消息堆积?
1.业务高峰期,请求量暴涨。
2.代码异常没有ack,或者全进入到死信。
# 7.2 怎么解决消息堆积问题?
1.通过适度调高并发参数,提高服务消费能力。一般调整预取值prefetch和并发线程数concurrentcy。
2.增加消费节点,在数据库等扛得住的情况下,增加消费服务是一个优先选项。
3.异常导致的消息堆积,先紧急回滚代码,或紧急修复异常,然后按前两步提高消费能力。
# 8 什么是AMQP协议?
Advanced Message Queuing Protocol,高级消息队列协议。是一个进程间传递异步消息的网络协议。
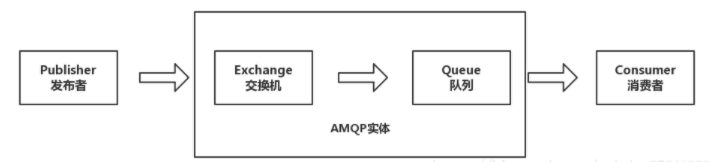
工作过程:
发布者(Publisher)发布消息(Message),经由交换机(Exchange)。
交换机根据路由规则将收到的消息分别发给与该交换机绑定的队列(Queue)。
最后 AMQP 代理会将消息投递给订阅了此队列的消费者(Consumer),或者消费者按照需求自行获取。
# 9 消息怎样才会进入死信队列?
1)队列消息长度到达限制。
2)消费者拒接消费消息,basicNack/basicReject,并且不把消息放入原目标队列,requeue=false。
3)原队列存在消息过期设置,消息到达超时时间未被消费。
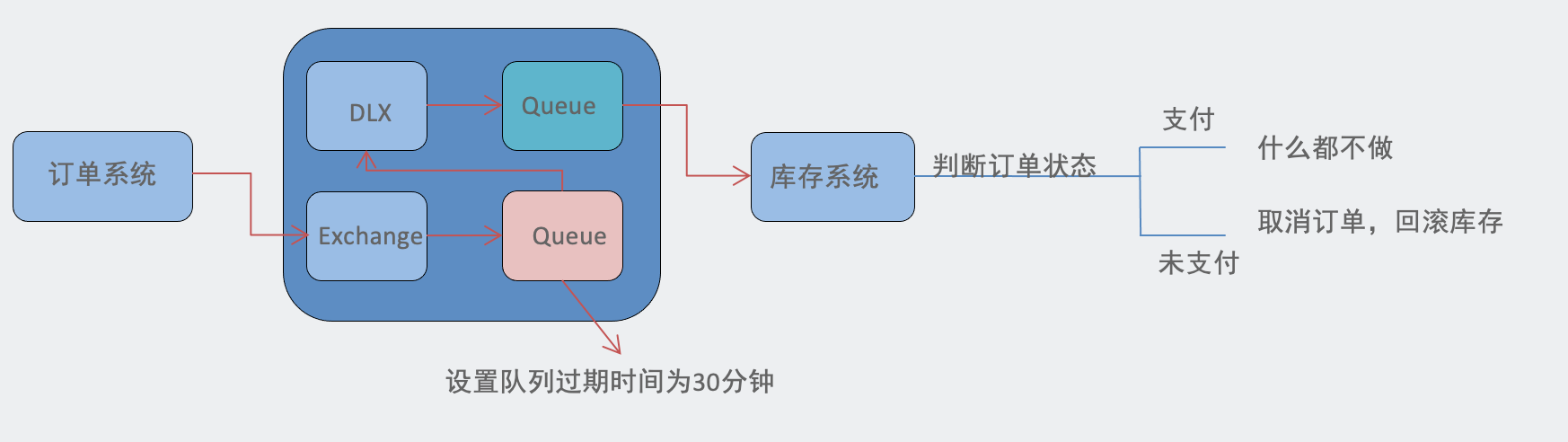
# 10 RabbitMQ延迟队列是怎么实现的?
使用TTL+死信队列组合实现延迟队列效果。
TTL(time to live)消息存活时间:
如果消息在存活时间内未被消费,则会被清除。
RabbitMQ支持两种ttl设置:单独消息配置ttl;整个队列配置ttl(居多)
需求:
1.下单后,30分钟未支付,取消订单,回滚库存。
2.新用户注册成功7天后,发送短信问候。
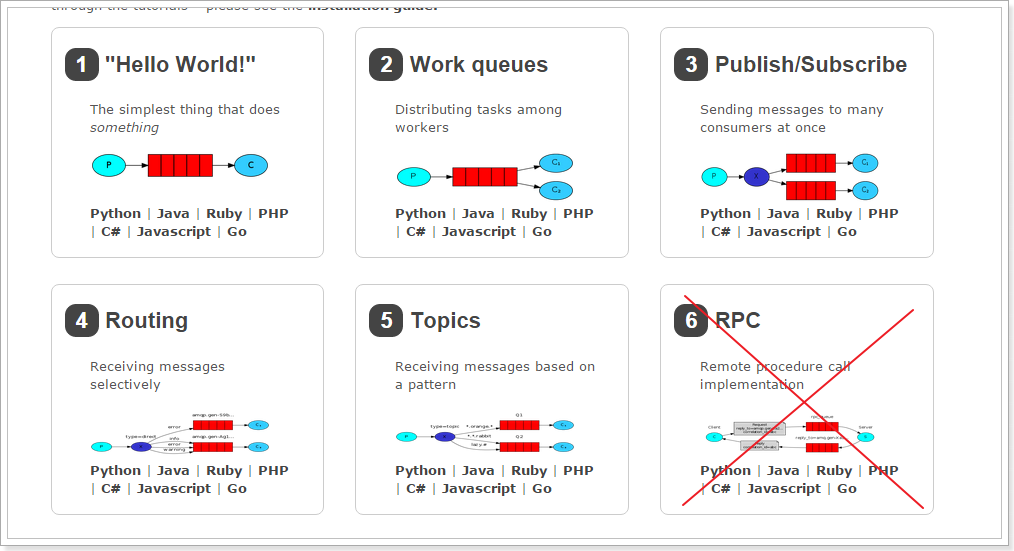
# 11 RabbitMQ有哪些工作模式?
简单模式
work queue
publish/subscribe发布订阅模式
routing路由模式
topics 主题模式
rpc远程调用模式
# 12 RabbitMQ怎么保证高可用?
# 12.1 普通集群模式(不能保证高可用)
在多台机器上启动多个RabbitMQ实例,每个机器启动一个创建queue只会放在一个RabbitMQ实例上,但是每个实例都会同步queue的元数据。
消费的时候,实际上如果连接通另一个实例,那么就会从queue所在的实例上去拉取数据,如果那个放queue的实例宕机了,就会导致其他实例无法从这个实例上拉取实际。
这个方案主要是提高吞吐量
# 12.2 镜像集群模式(高可用)
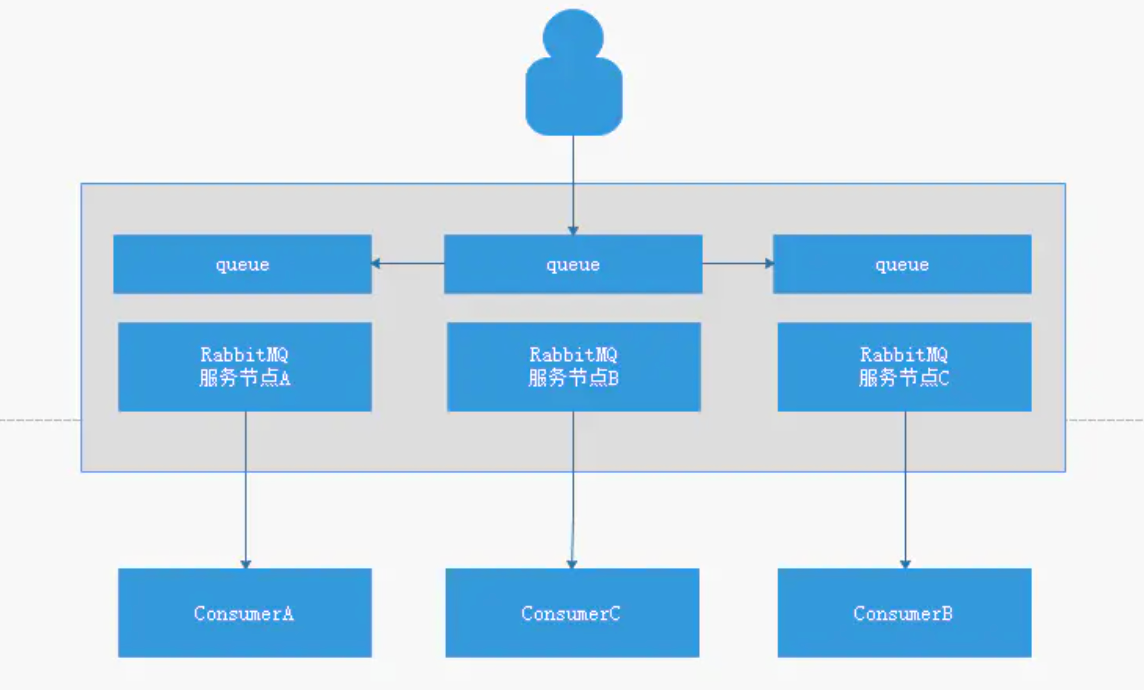
1.生产者向任一服务节点注册队列,该队列相关信息会同步到其他节点上。
2.任一消费者向任一节点请求消费,可以直接获取到消费的消息,因为每个节点上都有相同的实际数据。
3.任一节点宕机,不影响消息在其他节点上进行消费。
缺点
性能开销非常大,因为要同步消息到对应的节点,这个会造成网络之间的数据量的频繁交互,对于网络带宽的消耗和压力都是比较重的。
没有扩展可言,rabbitMQ是集群,不是分布式的,所以当某个Queue负载过重,我们并不能通过新增节点来缓解压力,因为所以节点上的数据都是相同的,这样就没办法进行扩展了。
对于镜像集群而言,当某个queue负载过重,可能会导致集群雪崩,那么如何来减少集群雪崩呢?我们可以通过HA的同步策略来实现
HA的同步策略如下

# 13 RabbitMQ怎么保证消息消费的顺序性?
1.RabbitMQ的queue本身就是队列,是可以保证消息的顺序投递的。
2.但是顺序消费就是另一回事了,要保证顺序消费可以通过以下做法:
1)投递消息的时候加上时间戳,消费端通过时间戳判断先后顺序。
2)同一字段的更新,设定只有一个消费者,但是这样效率低。